
| Home | Projects | Research | Misc. | Contact |
Cache Utilisation
Leveraging Caches for Faster Processing of Large Data Sets
[homac, ~2011]
Obviously, caches provide best performance if the number of cache hits is high. When processing larger amounts of data on a single processing unit the cache will soon reach its capacity limit and the number of cache misses constantly raises. Thus, to lower the amount of data to be handled by a single cache a simple approach is to distribute processing on more processing units. (Of course, this depends even on the caching algorithm, scheduling strategies used by the runtime environment, e.g. runtime library, VM, OS and hardware, but for large amounts of data it is always true).
The following results from measurements of an example written in Java provides a more hands-on view on this thesis. This example performs a task which does not allow parallelisation. This task is performed single threaded and on 28 threads but sequentially in both cases. The same task were performed a thousand times on the same memory region but with different values. In the multi-threaded scenario, the main thread creates 28 worker threads, assigns 1/28th of the data to each of them and synchronously delegates processing to them sequentially until the last data portion is processed. The thread kept its part of the data until all 1000 iterations were performed. The following pseudo code snippet depicts it.
// Data distribution
ThreadPool threads = new ThreadPool(28);
int part = data.length/28;
for (Worker w : threads) {
w.assign (data, i*part, (i+1)*part);
}
for (int i = 0; i < 1000; i++) {
// Start measure
int result = 0;
for (Worker w : threads) {
w.perform(result); // result = input parameter
result += w.receiveResult(); // wait for processing result
}
// Stop measure
}
Each thread was constantly running which reduces the probability that a thread will move to another CPU and it avoids latency to resume threads after suspension. Thus, synchronisation between threads, e.g. to exchange input parameters on delegate and the return value on finish, were realized with a spin lock using a volatile variable.
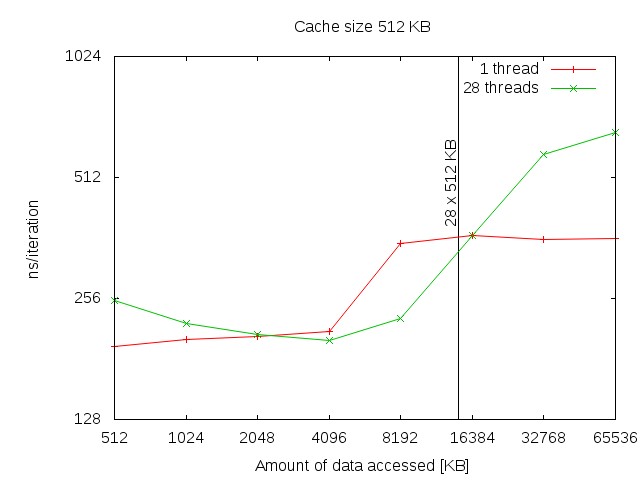
The measurement where performed on a shared memory system with 32 Opteron CPUs with 512KB cache. The first measurement of 512 KB (the size of the cache) shows the absolute overhead of about 30 ns produced by the multi-thread version, due to context switching and data exchange. The multi-threaded version performs better if the amount of data to be processed is about 8 times higher than the cache capacity. The vertical line in the graph depicts the boundary of the capacity of all the 28 caches of the multi-threaded version. Passing that boundary results in even higher overhead for the multi-threaded version.
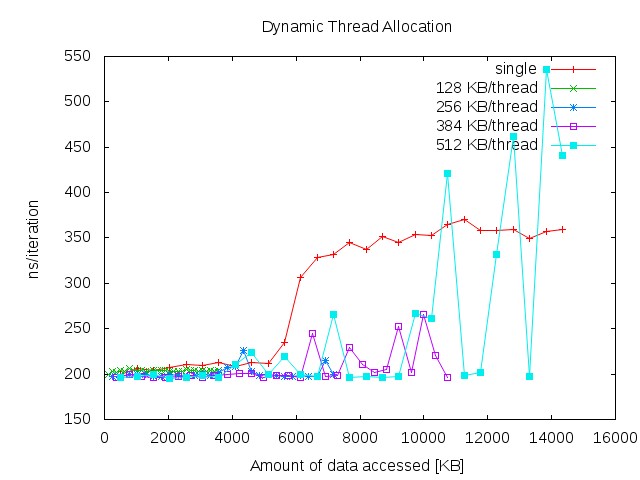
To get the most of the cache you need to calculate the optimal distribution of memory considering the switching latency. The next chart demonstrates the performance, if the amount of threads is dynamically calculated to achieve optimal cache load. Because not the whole cache is available for data and address caching there are multiple measurements each with another amount of data to be processed per thread.
Links
- Sources and binary in a jar
- Log files with measurement results: TC1@256KB, TC2@128KB, TC2@256KB, TC2@384KB, TC2@512KB
- Gnuplot scripts for the visualisation of the log file: chart 1, chart 2