
| Home | Projects | Research | Misc. | Contact |
Meta Diff Tool
Introduction
Updates are annoying because they are quite frequently and occupy various resources of the user's PC for a significant amount of time. Very often a user has to decide whether he ignores the update notification and takes the security risk of using vulnerable/buggy software or wait for the updates to complete.
While waiting for an update, he may wonder, why the download for a "bugfix" has almost the same size as the initial download of the entire software. A rough analysis of updates from various software distributors reveals that most of those updates are in fact complete software downloads, where some of them aren't even compressed or use weak compression methods. So, the user ends up downloading a bunch of redundant data.
Network bandwidth and connectivity are still an issue due to out-dated infrastructure (example: central Europe), limited bandwidth on broad-band cables over sea and overloaded network nodes (switches) in between. Thus, there is a significant amount of users who still suffer behind 10Mbit and less. Furthermore, an estimate of the potential savings through patches revealed, that even fiber cable networks would not be enough to make patches obsolete.
The ideal solution to this update debacle are actual patches, where the patch contains only those data portions, which are not yet on the local machine, accompanied by instructions on how to modify the old data, to achieve the new software state. As a result, a patch usually contains just a fracture of the size of the entire software.
Now, software developers/distributors obviously know about patches, but they also have good reasons to avoid them:
- Overall Complexity: Every new component in a system adds a new potential source of errors. A patch (or even just decompression) can fail for various reasons: unexpected modifications on client side, different tool version, different encoding, different processing architecture, etc. pp. .
- Multiple Software Versions: With millions of client you get several different software versions present on the client machines. Since a patch can only apply to one particular version you would need patches for each of those versions or a sequence of patches for the transition from - let's say - version 2 to 3 to 4 and finally to the current version. Thus, it either increases the complexity even further or the download gets bigger.
- Patch Creation Time: Creating a patch over tens of gigabytes of data takes a very long time. It can be compared to compression, which is a very similar task. So, you have to consider the time to be spend when you plan an update. But, lets say, the developers finished their job on time. Everything went well, patch was created (took along time), update is ready to be published. Suddenly one of the stupid QA guys stumbles in your office and tells you about a sever bug, which has to be fixed! The fix is just a minute or two but the whole upload and patch creation takes about an hour which throws all your plans off track.
- Patch Application vs. Download Time: Although, patching is very fast (compared to patch creation), it still requires at least some time. If the decrease in download time is less than the time required to patch the software, then a patch turns into a disadvantage.
- Complex Tools: Currently, there are just a few tools, which can create patches for arbitrary types of binaries. They are called binary diff tools and create and apply patches for binaries. Those tools have several limitations, which cause them to be difficult to use effectively: Either the patch will get too large or the user has to manually select files to be analysed and patched by the tool. We will discuss this topic in more detail in another section below.
But what are the advantages or rather issues of not using patches.
- Lack of Transparency: Nowadays, most tasks require access to the Internet. Doing research on some topic, looking up manuals or code snippets while programming, checking emails, phone calls, socialising, casually watching videos, gaming, anything. A running download of several gigabytes of data significantly reduces the bandwidth and thereby makes those tasks either quite annoying or even impossible. Thus, updates aren't actually transparent, even if they run in the background.
- Time to Run: Users usually turn their PC on to do something. Once booted, first thing that pops up is an update. Unfortunately, an update of the software you actually just wanted to use. Thus, instead of working on something, you are now sitting there with your cup of coffee, waiting for the update to finish (at least a good excuse).
- Security Risk: Security updates are important, we all know that, but sometimes the user decides that his/her current task is just more important than waiting for a download. This may have sever consequences not only for the user, but also for the involved software company.
All those issues rising from updates with excessive download times, add up and cause frustration on user side. User frustration, obviously, has negative effects on customer relationship in general. It affects the acceptance of bug-fixes and bugs in general. Everybody knows, that software may have bugs (since developers are human) and should be happy if they are fixed. But since every fix involves a disproportionately large update, users are rather frustrated about it and developers have to add at least something to make up for it.
Excessive update times also lower the willingness to download software in general. Online gaming companies which, for example, rely on micro-transactions, will have an interest, that users are willing to update to be able to access their service. But also, for example, when doing a quick purchase of a casual mini-game at late evening on weekend, people consider the time they have to spend waiting for the download. Since users do not really measure the time and calculate the expected download time, they will estimate it based on their experience. And their experience will be worse, the more time they have recently spend waiting for updates.
This breakdown of the current state, provides a lot of good arguments to reconsider the current update distribution process. The goal of this project is to tackle all the currently existing issues of patch creation, distribution and application by developing a procedure and a framework, which allows seamless integration into an existing update distribution process, with minimal or no effort. This will be mainly achieved by the introduction of a so-called delta service, which detects updates, generates deltas on client requests and distributes them when ready. Another major topic of this project is the development of a tool, which assists binary diff tools, when dealing with large and compressed software packages which usually produce bad results in patch creation. Not part of this project is the development of a diff tool. Algorithms for generic binary diffs have been researched in the past and the current state is good enough to provide significant advantages when used properly.
Issues of Binary Delta Calculation and Application
To understand the issues of binary diff tools and why those issues cannot be fixed by 'add more processors' or 'add more memory' we have to have a look at the task of binary delta calculation.

The overall process is quite simple. To create a patch, a diff tool analyses the differences in two files old and new and writes a sequence of instructions into a script. The script contains simple instructions, such as ADD <new-data> and COPY <range-in-A> and similar. This script, with the new data portions of file new, comprises the patch (old→new). When applying a patch, those instructions are executed by copying the required data portions of file old and concatenating them with the new data portions delivered with the patch according to the script. This finally produces file new.

Binary diff tools work quite similar to compression tools. The difference between both is, that binary diff tools look for similarities in two files, while compression tools look for similarities in one file. A simple compression algorithm could be to first gather all patterns found in the file. When finding the same pattern at a subsequent location in the file, it can replace that by a reference to the former location in the same file. This may lead to the following idea: Let's say, we have an older version of a file A and a new version of the same file B. By simply concatenating those two files A and B we get a single file AB which has a lot of similarities between the first half and its tail part. When compressing AB, the tail part (belonging to B) would only contain patterns, that were not found in the first part. Those are exactly the new patterns. Thus, the compressed tail, belonging to B can be used as patch. To apply the patch, we can now compress A again, append our patch (compressed B) and uncompress it to create AB. Removing A finally gives B. This actually works good for short files. But with longer files, the patch gets disproportionately large. The reason for that lies in the fact, that the number of patterns found in a file rises exponentially with its size. For example, a sequence of just three characters, such as abc already contains the following patterns: (a), (ab), (abc), (b), (bc), (c). Compression tools have efficient data structures to store patterns but the fundamental issue, that the amount of patterns in a file is just humongous, stays the same. Thus, compression tools, and diff tools, have to cut files into smaller pieces or just forget about patterns they have seen earlier to be able to keep memory utilisation and processing time reasonable.
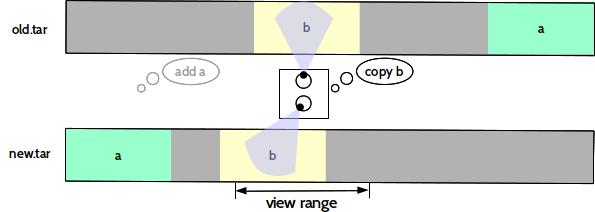
The limited view range of a "common subsequence algorithm" working on a file leads to a very common issue. Let's say we have created two tar archives with exactly the same content. The ordering of files in a tar file, depends on the order found in the directory node of the file system, containing them. Thus, we can end up having two tar balls with the same content but different order. Now, due to the limited view range of the delta algorithm, the patch ends up containing section a, even though it is available in the older version of the tar. As said, this is a common issue not just for tar archives, which makes patches over archives generally useless, unless special care was taken to keep data in the same order.
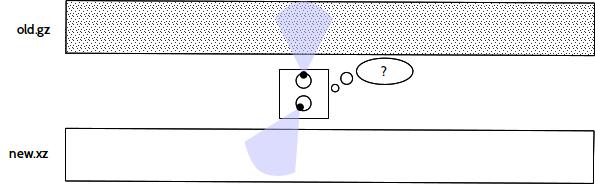
Another more obvious issue, is compression. Using a different version of the same compression library or even an entirely different compression tool than before, causes any similarity that may have existed in the original data, to vanish. There are approaches for diff tools, which consider uncompressing the data before analysing the content, but they have issues repacking them afterwards. Command line arguments, such as the compression level, method, memory utilisation aren't usually stored in the compressed file, because they are unnecessary at decompression time. Also, the compression method may have changed or header data may vary with each run (e.g. a time stamp).
Beyond those issues there are other, more domain specific issues. For example executables: Executables contain lots of static addresses, especially to call functions. When changing just one line of code in a function, all code addresses behind this particular change, will be offset by the amount of machine instructions generated by the compiler for the added code line. The tools bsdiff/bspatch address exactly this issue for executables or shared libraries, but there are similar issues in other application domains. For example, changing the tone in an image by lowering the saturation; moving/rotating a 3D model by altering all vertices of the object; increasing the amplitude of a sound sample. All those are examples for very specific modification characteristics. We believe, that there is a potential for a general diff algorithm (which would be extremely slow), but currently there are rather different approaches for each domain (or those can be derived from existing lossless compression methods of those domains). Thus, just having one binary diff tool, may not be the best you can get.
The various issues of delta creation and application depict the need for one particular improvement, that can be made: A tool which manages and controls the delta creation and application process. A tool which increases the similarity of data streams by normalising its content through unpacking, uncompressing and ordering. A tool which is capable to detect the steps required to properly repack formerly unpacked and uncompressed data, to produce the exact same and not just similar output. This would be some kind of meta-diff tool, which has its very own challenges, mostly driven by the lack of processing time, which will be discussed in another section.
Naive First Approaches
As explained in the previous section, the main reasons for binary diff tools to create patches with too much redundancy are:
- Compression and
- different ordering of files in archives.
Thus, an obvious approach is to unpack and uncompress data of the old and new package and create a diff over the resulting directories and files. To apply the patch, the old package will be unpacked again, and the resulting set of files will be patched and finally repacked to assemble the new package.

naive patch creation process
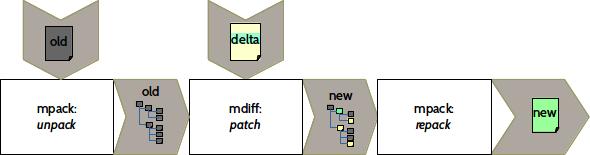
naive patch application process
To explain, why this approach is not sufficient to compete with simple downloads of full packages, we have to have a closer look at each step of the process and the data that is generated throughout.
Process Outline
- Patch Creation
- Unpack old package.
- Unpack new package and keep information to repack it.
- Calculate delta over resulting set of files and store in patch.
- Patch Application
- Unpack old package.
- Apply patch to files of unpacked package.
- Repack patched files according to repacking information.
Unpacking
Unpacking a package is simply identifying the proper tool and run it to get the unpacked set of files. Since a package can contain other packages, this process has to be recursive. Thus, after unpacking on first level, the unpacked result has to be traversed to identify and unpack contained packages. For the convenience of further processing, unpacked files of each package are stored in a directory with the name of the package at the same location of the package in the directory tree of the unpacked top-level package as shown in the following example.
Example
Let's say,archive.tar.gz is a gzip compressed archive, containing a directory
dir with files
a and
b. Unpacking then produces the following directory structure:
archive.tar.gz : gzip
|
+-- archive.tar : tar
|
+-- dir : dir
|
+-- a : file
|
+-- b : file
Unpacking for Repacking
To be able to create an identical copy of a package, that was unpacked during the process, various information about the original package is required:
- Tool: Identification of the tool or library, such as
tar, gzip or liblzma2. - Version: Version of the tool.
- Arguments: Command line arguments or function call parameters (e.g. file name, compression level or method, header data, etc.).
- File Ordering: Order of files as found in the original package.
- File Attributes: Attributes, such as permissions, owner or timestamps.
- File Type: Especially for hard links and soft links, since their representation may differ on the present operating system.
File order, type and attributes are usually required to repack archives. File type and attributes can be different when unpacked (such as owner==root) and have to be recorded from the package (e.g. archive), which contained them.
To obtain this repacking information, an analysis of the original package is required. This analysis involves repacking for comparison, not only for verification. For example, to determine an unknown compression level, we can compress the uncompressed file with different compression levels and compare the results to the original package until we find an exact match. Or in cases where a tool adds varying information on each run (such as a timestamp in a header), we can identify and copy that particular data portion to patch it in when repacking.
The given examples of package analysis procedures are very basic and can be much more efficient. But they show, that the effort to obtain required repacking information can be quite significant (up to several minutes, depending on type and size of data). Fortunately, package analysis has to be done only once, and only when creating the patch. Thus, the patch application time is not affected by it.
Delta Calculation
There are two approaches to calculate the data over those unpacked directories:
- Recursive Delta: Here we traverse over the set of files in both directories and create deltas for individual files. At the same time, we keep track of changes on file system level, such as file was deleted or added or it was turned into a link and changes of file attributes. This is basically, what the Unix
difftool does when running with argument--recursive. - Stream Delta: In this approach, we also traverse over both directories, but this time we concatenate all files in a stream -- one for each directory. The delta is then calculated over those two streams instead of each individual file. To avoid the issues with file order during delta creation, the files in each stream are ordered by name. Those streams (currently just tar files) also contain file attributes. Thus, the resulting patch file implicitly contains both: changes in file content and its attributes.
Both approaches have advantages and disadvantages. Due to sorting by file name, stream delta implicitly avoids cases, where file names where just slightly changed, such as a version number suffix or lower case to upper case. And even if the file name changed entirely, there is still a chance, that the file is inside the view range of the diff algorithm, when processing the streams. But there are of course cases, where the position of files in the streams has changed due to insertions and deletions and thereby went beyond the view range. In this particular case, the recursive delta produces better results. But, as an analysis has shown, individual deltas for each file are in average a disadvantage, because of redundant information added by them (e.g. name of the original files and checksums). Also, the number of file system operations is significantly higher, which makes recursive deltas slower.
Main Disadvantages of These Approaches
The goal is to compete with downloads of full updates. Thus, patch download and application time has to be lower than the download time of a full update. While the download time mainly depends on the network bandwidth, patch application time depends mainly on the runtime performance of the underlying file system. This however, depends on the following factors:
- Unpacking effort: If a package is just one large archive, then unpacking requires to read the entire package and write it to the file system, each file once. If the package contains more packages, then unpacking has to read each contained package again and write its files to the file system again. Thus, recursively unpacking the whole package can produce a multitude of the effort of for example just copying a package once. If a package is not compressed (just contains archives) a reasonable maximum effort will be two times the effort of copying. If the data is compressed too, a reasonable maximum effort depends on the size of the uncompressed data, because decompression has almost the same costs as copying (depends on the tool too). Since compressed data cannot be more compressed by compressing it twice, the reasonable maximum then lies by
reasonable maximum unpacking time = 3 * unpacked size * copy time/byte
It is now three times, because a compressed file uncompresses into a file, which most likely will be an archive and has to be read again. We use the term reasonable maximum, because practically a package can contain a package which contains another package and so forth (e.g. something likearchive.tar.gz.tar.tar.zip), but that is not reasonable. - Patching effort: Both patching methods have different efforts:
- Stream Delta: Since the binary diff tools do not support actual stream processing, we have to create an archive of both unpacked directories and store them on the file system, before running a patch tool over it.
streaming time = 1 * old unpacked size * copy time/byte
The patch tool copies fragments from the old file (archive) and fragments delivered with the patch and copies them into a new file (archive). In total it copies exactly the same amount of data as the size of the resulting new file.patch tool time = 1 * new unpacked size * copy time/byte
Finally the stream gets again written to the file system, to create the directory, which has to be repacked later.unstreaming time = 1 * new unpacked size * copy time/byte
Considering, that the new package has roughly the same size as the old package, this sums up to an estimated total patch time of:total patch time = 3 * unpacked size * copy time/byte
- Recursive Delta: A recursive delta does not need to assemble and disassemble a stream. Thus the only processing effort lies in patching of modified files and adding/removing files. Thus, the estimated total patch time is simply:
total patch time = 1 * unpacked size * copy time/byte
- Stream Delta: Since the binary diff tools do not support actual stream processing, we have to create an archive of both unpacked directories and store them on the file system, before running a patch tool over it.
- Repacking effort: Repacking is roughly the same as unpacking, just in reverse order. Thus, it produces almost the same effort in terms of controlling the repacking process, except that compression requires significantly more time than uncompression. The exact effort depends on the compression level and method, and the redundancy of the data. Roughly, compression is up to 1000 times the copy effort. Since packages can contain packages, this multiplies with the amount of times, the data was compressed. For example, an update package is usually compressed and may contain compressed packages too. Those contained packages may again contain directories, which contain compressed files. This is case is quite common and thus, the (reasonable) maximum repacking effort sums up to:
approximated maximum repacking effort = 3 * 1000 * unpacked size * copy time/byte
Thus, compression during repacking is the main bottleneck in the whole patching process. That makes a sequential patching process lose in competition to full updates when the patch is close to 80% of the size of the whole package. Therefore the next approach will aim for more parallelism. While a sequential process waits for the patch download to complete, before even starting to work, a parallelised process can already start, while the download is running and almost be finish when the last bit of the patch arrives. Thus, the additional patching effort, when considering the time, is close to null. The processing effort will of course be higher, but not considerably, because of the rather slow network I/O, which will suspend the process from time to time.
Sequential vs. Parallel Patching
Evaluation of the runtime performance of the sequential prototypes introduced in the previous section provided devastating results for patches of debian packages. Further analysis revealed compression and decompression as the main bottleneck which lead to a new parallel approach. The parallel approach can optimise the process down to the point that everything runs truly parallel to the download of the patch. Therefore, the compression effort only comes into account, when it is slower than the download. Because the compression run, which would compress the whole package after patching would require the longest time, we just need to consider this last compression run. All the other compressed files in compressed packages can be handled in parallel.
Based on the results of preliminary analysis and the fact, that the decompression and compression are the main bottleneck, we can approximate the patching effort for a sequential and a parallel patch process as follows:
- Sequential Patching:
-
patch_time_seq = patch_download_time + decompress_time + compress_time - Parallel Patching:
-
patch_time_par = max(patch_download_time, compress_time)
Compression and decompression time was measured in a different analysis on recent hardware (Intel(R) Core(TM) i7-3770K CPU @ 3.50GHz, 8MiB cache size) using xz and gzip. The times used for this approximation here are:
| min | avg | max | |
|---|---|---|---|
| decompression [sec/MiB] | 0.0080 | 0.0300 | 0.1100 |
| compression [sec/MiB] | 0.0400 | 0.2500 | 0.6500 |
All times refer to the time in seconds required to process 1 MiB of uncompressed file size. Thus, in decompression, the output counts and not the input.
It has to be mentioned here, that maximum and average compression time are by the most part negatively influenced by xz while gzip always delivered superior response times, much closer to the raw copy time of a file of the same size. Since gzip and xz both derived their compression algorithm from LZ77, it can be assumed that xz probably can run faster. But since other compression tools haven't been tested yet, the average times can be assumed to be a good approximation.
Download time was approximated by the maximum bandwidth for 6, 10 and 100 mbit/s (accordingly 1.33, 0.80 and 0.08 sec/MiB).
Based on these times, the patching time was approximated for the different (de-)compression times (min/avg/max), different network bandwidths and different patch size ratios (ratio = patch size/package size). The download time of a full update (full package download) was added to each graph for comparison.
Best Case
These graphs consider minimum values for (de-)compression times. At 6 and 10 mbit network bandwidth, both approaches are very close to each other and clearly outperform a full update. At 100 mbit/s a sequential process can only compete with a full update, if the patch size is less than 40% of the package size. The parallel approach, can safe up to 50% of the time compared to a full download. At that point it hits the compression time boundary, where the compression requires more time than the patch download. This boundary only exists, if a package is compressed. Otherwise, patches of less size can improve patch time even further.



Average Case
These graphs consider average values for (de-)compression times the sequential process was considered to have to compress packages two times (compressed file in compressed package). A sequential patching process can only compete with full updates, if patch sizes are below 55% the update size at 6 mbit/s and below 30% at 10 mbit/s. In contrast, a parallel patching process still outperforms a full update and safes up to 75% of the time at 6 and 10 mbit/s. However, at 100 mbit/s there is no longer any timely advantage in using patches, if the packages are compressed.



Worst Case
These graphs consider maximum values for (de-)compression times, and the sequential process was considered to have to compress packages three times (compressed file in compressed package). The sequential process can no longer compete with a full download at whatever network bandwidth, but the parallel process still can: At 6 mbit/s it can improve update times up to 38% befor it hits the compression time limit at 50% patch size ratio. At 10 mbit/s it can achieve only up to 15% time saving and at 100 mbit/s it is always slower than a full update. Again, this applies only to compressed packages and if xz is a proper representative of a worst case compression tool.


